Тест Мобильного клиента (SIMP HMI)

Тут оставляем сообщения об ошибках, пожелания по доработке/
Описание настройки в статье по адресу:
Тут оставляем сообщения об ошибках, пожелания по доработке/
Описание настройки в статье по адресу:
Пришлите HWID аппарата на почту, посмотрим изменился ли
и заодно модель устройства и версию ОС на нем.
После официального OTA обновления ОС мобильного аппарата, слетела лицензия, так должно быть?

мда... странный прибор.
в первом релизе точно формул не будет. дальше - возможно будут, а возможно нет.
В данный момент могу посоветовать только записывать значения с поменянными старшим и младшим байтом. Увы, но другого пути нет.
Подскажите, каким образом можно будет отображать в HMI дробные значения, если не будет формул?
оптимизатор:
None - отсутствие оптимизатора. т.е. каждый адрес запрашивается отдельным пакетом данных. это самый тормозной способ. т.к. необходимо дожидаться пока придет предыдущий ответ и только потом отправлять следующий. Но он нужен для тех приборов, которые не поддерживают множественное чтение.
Data - симп анализирует карту заданных адресов и пытается группировать адреса для запроса одним пакетом. при этом при разрывах в карте адресов - формируется отдельный пакет. т.е. например, заданы адреса 1, 2, 5, 6 - будут сформированы 2 пакета для адресов 1, 2 и для 5, 6.
Full - то же что и Data, но разрывы в карте адресов могут быть включены в пакет (если программа решит что ей выгоднее спросить несколько "лишних" адресов, чем разбивать данные на несколько пакетов). т.е. для адресов 1, 2, 5, 6 будет сформирован один пакет. в нем также придут "лишние" данные - адреса 3 и 4. но их значения будут отброшены. По количеству передаваемых данных - это самый оптимальный вариант. Но он работает не на всех устройствах.
если устройство не поддерживает множественное чтение - то однозначно оптимизатор надо отключать (None).
если поддерживает - то Data или Full. это зависит от того, как обрабатывает запросы к несуществующим адресам само устройство. Есть устройства, которые при запросе несуществующих адресов возвращают ошибку. Например, заданы адреса 1, 2, 5, 6 - то любое чтение (даже множественное с 1 по 6) - возвратит ошибку. Для таких устройств подойдет только оптимизация Data. Ну или надо делать карту адресов без разрывов. Тогда подойдет Full, но работать будет точно так же как и Data.
Full может реально ускорить работу, если адреса заданы через 1. Тогда Data будет работать как None. На каждый адрес будет отдельный запрос. А Full - сгруппирует по возможности чтение. Но таких ситуаций следует избегать.
Побочный эффект множественного чтения - обновление данных может быть гораздо быстрее чем указано при настройке канала. Например адреса 1 и 3 настроены на 1 сек. а адрес 2 - на 2 сек. При групповом чтении все 3 адреса будут обновляться с частотой 1 сек.
Это надо учитывать. И если это нежелательно - группировать адреса с одной частотой опроса близко друг к другу.
Теперь понятно, благодарю за ответ!
Хотя нет, беру слова обратно. Изменил настройки modbus драйвера, было так:
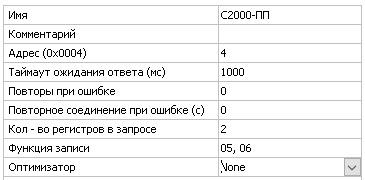
Сделал так(как в прошлом проекте):
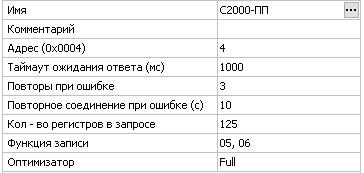
Начал отрабатывать корректно, в плане управления, даже через интернет.
А не объясните что такое оптимизатор данных? Где какой и по какой причине применять тот или иной? А то в справке я этого не нашел.
оптимизатор:
None - отсутствие оптимизатора. т.е. каждый адрес запрашивается отдельным пакетом данных. это самый тормозной способ. т.к. необходимо дожидаться пока придет предыдущий ответ и только потом отправлять следующий. Но он нужен для тех приборов, которые не поддерживают множественное чтение.
Data - симп анализирует карту заданных адресов и пытается группировать адреса для запроса одним пакетом. при этом при разрывах в карте адресов - формируется отдельный пакет. т.е. например, заданы адреса 1, 2, 5, 6 - будут сформированы 2 пакета для адресов 1, 2 и для 5, 6.
Full - то же что и Data, но разрывы в карте адресов могут быть включены в пакет (если программа решит что ей выгоднее спросить несколько "лишних" адресов, чем разбивать данные на несколько пакетов). т.е. для адресов 1, 2, 5, 6 будет сформирован один пакет. в нем также придут "лишние" данные - адреса 3 и 4. но их значения будут отброшены. По количеству передаваемых данных - это самый оптимальный вариант. Но он работает не на всех устройствах.
если устройство не поддерживает множественное чтение - то однозначно оптимизатор надо отключать (None).
если поддерживает - то Data или Full. это зависит от того, как обрабатывает запросы к несуществующим адресам само устройство. Есть устройства, которые при запросе несуществующих адресов возвращают ошибку. Например, заданы адреса 1, 2, 5, 6 - то любое чтение (даже множественное с 1 по 6) - возвратит ошибку. Для таких устройств подойдет только оптимизация Data. Ну или надо делать карту адресов без разрывов. Тогда подойдет Full, но работать будет точно так же как и Data.
Full может реально ускорить работу, если адреса заданы через 1. Тогда Data будет работать как None. На каждый адрес будет отдельный запрос. А Full - сгруппирует по возможности чтение. Но таких ситуаций следует избегать.
Побочный эффект множественного чтения - обновление данных может быть гораздо быстрее чем указано при настройке канала. Например адреса 1 и 3 настроены на 1 сек. а адрес 2 - на 2 сек. При групповом чтении все 3 адреса будут обновляться с частотой 1 сек.
Это надо учитывать. И если это нежелательно - группировать адреса с одной частотой опроса близко друг к другу.
Я вот так и сделал, читаю с младшего, вижу нормальные значения, формулу убрал, на запись все равно два значения, не запутаюсь, записываю 6144 и 27904, функции на запись 05, 06 и для ПК и для HMI, а вот когда использовал формулу на чтение и записывал 24 и 109 соответственно, с мобильного клиента требовалось использовать функции записи 15,16, мы выше обсуждали проблему, то что не с первого нажатия значение записывается, сначала записывался 0 потом уже 24/109.
Lantan этот, тормозит, через раз записывает, по своему живет. Через инет так и не записал я значение, хотя отображение есть. В общем отказываюсь я от этой идеи. Вам спасибо за ответы.
Хотя нет, беру слова обратно. Изменил настройки modbus драйвера, было так:
Сделал так(как в прошлом проекте):
Начал отрабатывать корректно, в плане управления, даже через интернет.
А не объясните что такое оптимизатор данных? Где какой и по какой причине применять тот или иной? А то в справке я этого не нашел.
мда... странный прибор.
в первом релизе точно формул не будет. дальше - возможно будут, а возможно нет.
В данный момент могу посоветовать только записывать значения с поменянными старшим и младшим байтом. Увы, но другого пути нет.
Я вот так и сделал, читаю с младшего, вижу нормальные значения, формулу убрал, на запись все равно два значения, не запутаюсь, записываю 6144 и 27904, функции на запись 05, 06 и для ПК и для HMI, а вот когда использовал формулу на чтение и записывал 24 и 109 соответственно, с мобильного клиента требовалось использовать функции записи 15,16, мы выше обсуждали проблему, то что не с первого нажатия значение записывается, сначала записывался 0 потом уже 24/109.
Lantan этот, тормозит, через раз записывает, по своему живет. Через инет так и не записал я значение, хотя отображение есть. В общем отказываюсь я от этой идеи. Вам спасибо за ответы.
А будет поддерживать?
Объясню на примере. С2000-ПП, два состояния, 24 взят (шс на охране), 109 снят. Добавляю тег, если читать с младшего байта то получаю 24 или 109, все как надо, а вот запись идет со старшего байта, приходиться записывать значения 6144 и 27904, а не те же 24 и 109, это не удобно. Поэтому считываю со старшего байта, добавляю формулу, чтоб из 6144 и 27904 получить 24 и 109 в Мониторе, на запись при этом формула не нужна, при чтении со старшего байта записываются значения 24 и 109, как в таблице, в общем я один раз применил формулу, а дальше работаю со значениями описанными в РЭ на С2000-ПП. Как то так, если поняли конечно). Не на эмуляторе в винде все работает как надо.
мда... странный прибор.
в первом релизе точно формул не будет. дальше - возможно будут, а возможно нет.
В данный момент могу посоветовать только записывать значения с поменянными старшим и младшим байтом. Увы, но другого пути нет.
Пришлите HWID аппарата на почту, посмотрим изменился ли
и заодно модель устройства и версию ОС на нем.
HWID в понедельник пришлю. Аппарат Google Pixel, android 8.0.0.